Subgradient and subdifferential
In convex optimization, the subgradient generalizes the concept of the derivative to non-differentiable functions. While smooth functions have unique gradients at every point, non-differentiable convex functions can have multiple subgradients at a given point.
Definition
A vector
The set of all subgradients at
This means that every subgradient forms a linear underestimator of the function, touching or staying below the function graph at
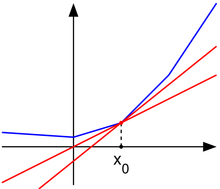
Geometric Interpretation
- The subgradient generalizes the tangent plane to convex functions that are not differentiable.
- If a function is differentiable at
, the subdifferential contains a single element — the gradient . - If a function is not differentiable at
, the subdifferential contains multiple subgradients, forming a set of supporting hyperplanes.
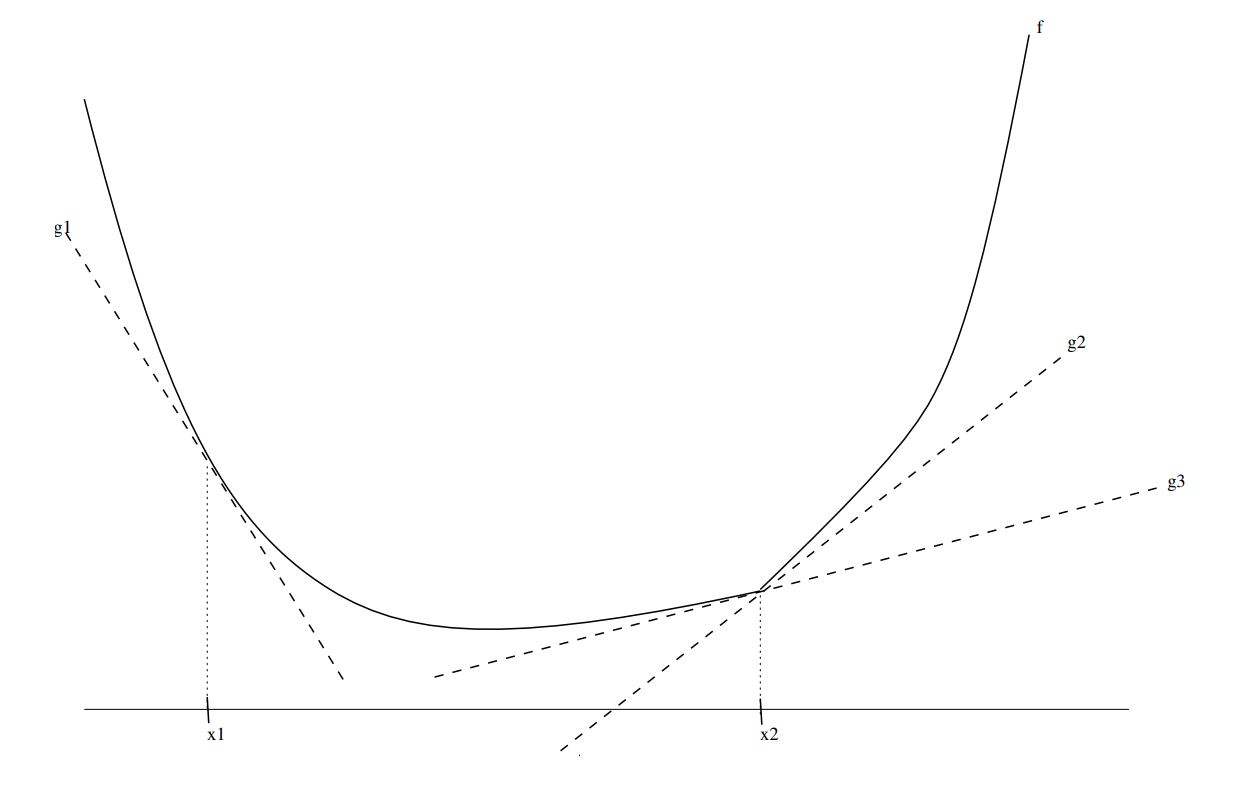
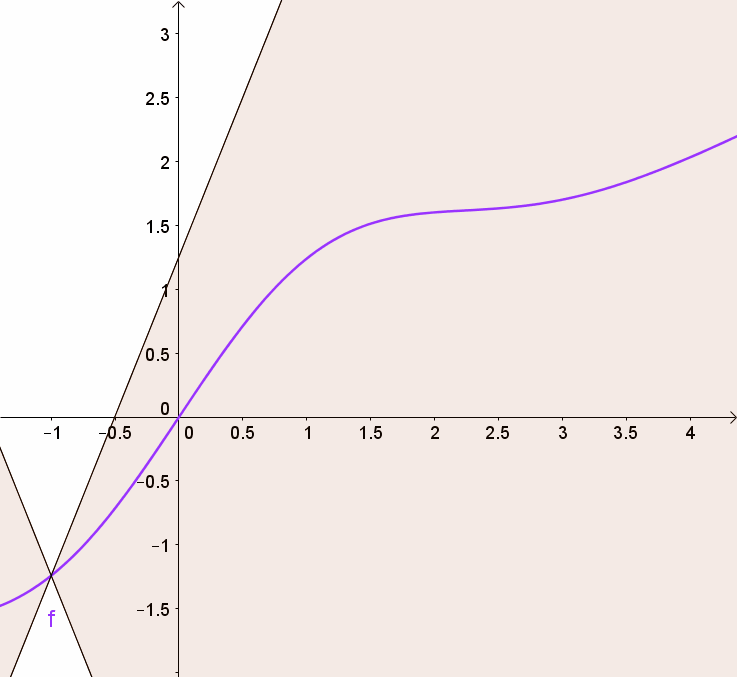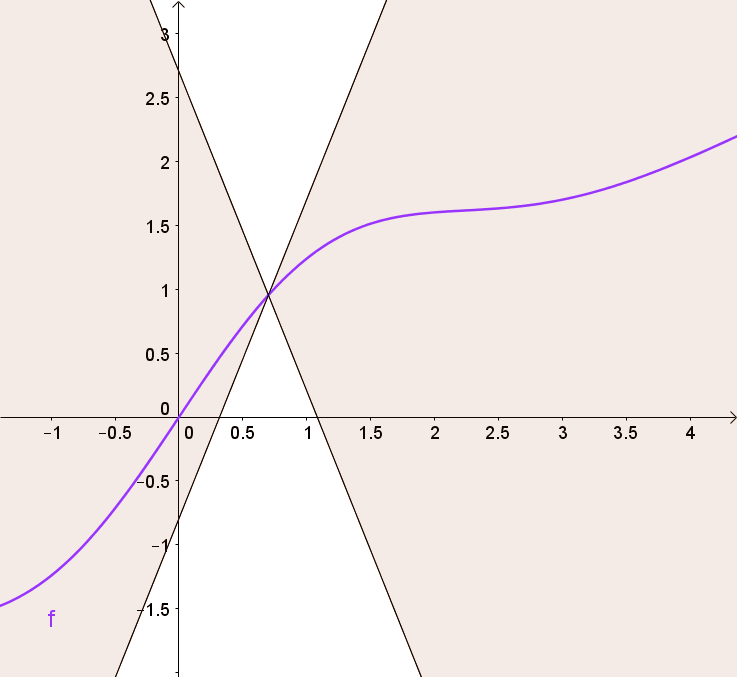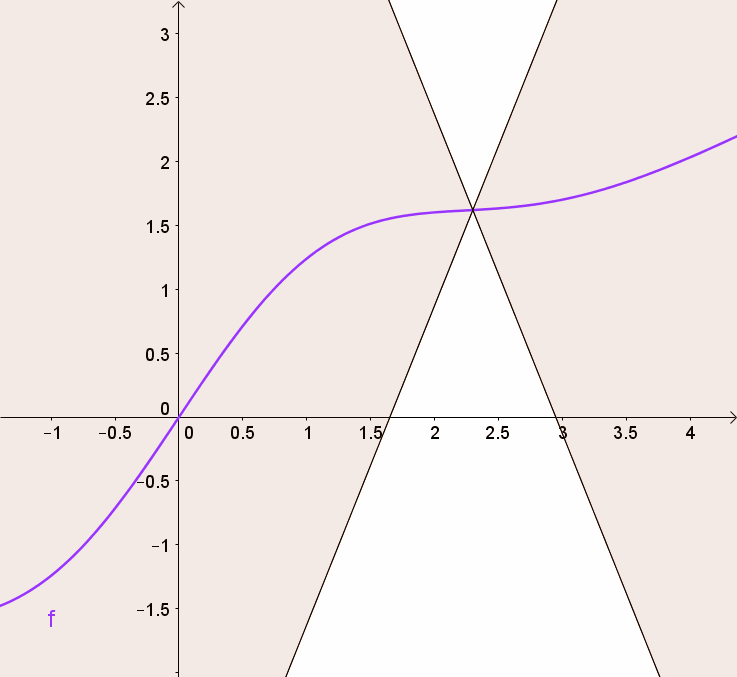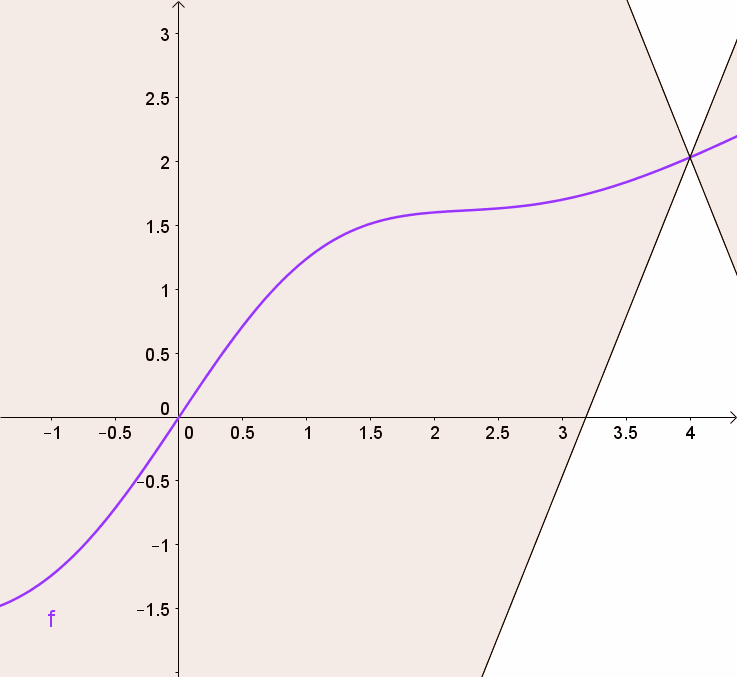
In the diagram:
is a subgradient at . Function is differentiable at , so is the gradient. and are subgradients at (since there are multiple valid supporting hyperplanes).
Subgradient Characterization of Convexity
The subdifferential provides a characterization of convexity:
Lemma 1
If
The set of subgradients could be empty if the function is not convex.
That's why this is a subset of the gradients.
It could be
Lemma 2
A function
is convex, and - The subdifferential is nonempty for all
:
This means that a function is convex if and only if it has at least one supporting hyperplane at every point in its domain.
Convex and Lipschitz Functions Have Bounded Subgradients
For convex and Lipschitz functions, the subgradients are bounded by the Lipschitz constant.
Lemma 3
Let
-
The norm of every subgradient is bounded:
-
The function satisfies the Lipschitz condition:
This means that for Lipschitz-continuous convex functions, the subgradients cannot be arbitrarily large — they are always bounded by the Lipschitz constant.
Subgradient Optimality Condition
For convex functions, the subgradient can be used to determine optimality.
Lemma 4
If
then
This means that if the zero vector belongs to the subdifferential, the function has no lower values, ensuring that
Summary
| Property | Meaning |
|---|---|
| Subgradient condition | |
| Subdifferential | The set of all subgradients: |
| Differentiability and subgradients | If |
| Characterization of convexity | A function is convex if and only if its subdifferential is nonempty everywhere. |
| Bounded subgradients | If |
| Optimality condition | If |
Subgradients extend gradients to non-differentiable convex functions, making them a fundamental tool in non-smooth optimization. 🚀