STEEPEST GRADIENT DESCENT
Steepest gradient descent is a variation of the gradient descent method where the step size is not fixed but instead chosen dynamically at each iteration. This approach ensures that the algorithm takes the most efficient step towards the minimum in each iteration.
Update Rule
The update rule for steepest gradient descent is given by:
where the step size
This means that at each iteration, we find the optimal step size
Geometric Interpretation
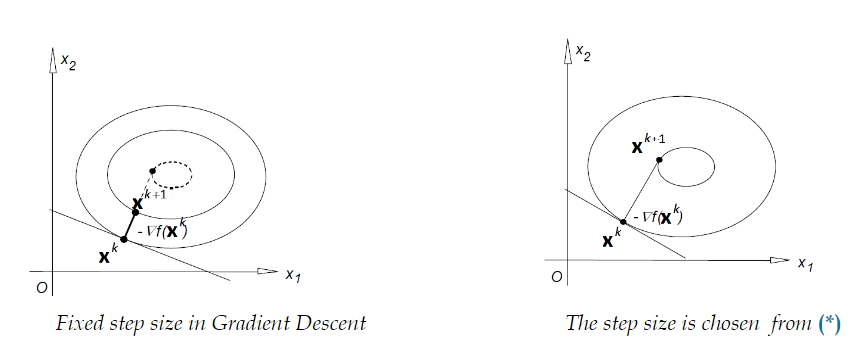
The two images illustrate the difference between fixed step size gradient descent and steepest gradient descent:
-
Fixed Step Size in Gradient Descent:
- The step size is constant across all iterations, leading to potential inefficiencies in convergence.
-
Adaptive Step Size in Steepest Gradient Descent:
- The step size is chosen optimally at each iteration, ensuring more efficient movement towards the minimum.
Convergence Properties
Theorem:
Let
This means that in the worst case, steepest gradient descent has a linear rate of convergence.
What Does This Mean?
- The order of convergence describes how fast the error decreases as the algorithm progresses.
- If the order of convergence is 1, it means the error decreases linearly in the worst case.
- This implies that steepest gradient descent is not always very fast—it may take many iterations to reach an accurate solution, depending on the function.
Modification: Step Size Reduction (Step Shredding)
A practical modification of steepest gradient descent involves step size reduction, also called step shredding. Here, the step size is adjusted dynamically based on a condition:
where
Very often,
This condition ensures that each step results in sufficient function decrease.
If the condition is not satisfied, we reduce the step size
The parameter
Very often, the reduction factor
Why is this modification useful?
- If
is too large, we may overshoot the minimum, leading to oscillations or divergence. - If
is too small, convergence becomes slow and inefficient. - The step reduction rule ensures we adapt to the function landscape, preventing large, ineffective updates while still making steady progress.
Algorithm for Modified Steepest Descent
-
Initialize
, an arbitrary step size (the same in all iterations), and parameters . -
For each iteration
: Set initial
.
Compute the update:Check if the inequality:
is satisfied.
If satisfied: acceptand move to the next iteration.
If not satisfied: reduce step sizeand repeat.
This method ensures that the step size is sufficiently large for fast convergence while also ensuring descent in function value.
Practical Insights
- The modification using step shredding makes steepest gradient descent more robust.
- Requirement
is stricter than , but both ensure function decrease. - This version of gradient descent is widely used in practice due to its adaptive nature.
Steepest gradient descent dynamically adapts the step size, ensuring that the optimal step length is chosen at each iteration, leading to faster and more efficient convergence.
Simple Example of the Algorithm
Finding the Minimum of
Let’s minimize:
using Modified Steepest Descent.
Step 1: Initialize Parameters
- Choose an initial point:
- Initial step size:
- Set
, .
Step 2: Iterate
-
Compute Gradient:
At
: -
Compute Update:
-
Check Descent Condition:
Since the condition fails, we reduce
Then repeat the update with the smaller step size.
Step 3: New Update with Reduced
-
Compute New Update:
-
Check Descent Condition Again:
Since the condition holds, we accept