SUBGRADIENT DESCENT
Subgradient descent is an extension of gradient descent for non-smooth convex functions. Unlike classical gradient descent, which requires differentiability, subgradient descent allows optimization over functions that have kinks or discontinuities in their gradients.
The Subgradient Descent Algorithm
Given an initial point:
and a subgradient:
the update rule follows:
where
Important Note:
Negative subgradients are not necessarily descent directions.
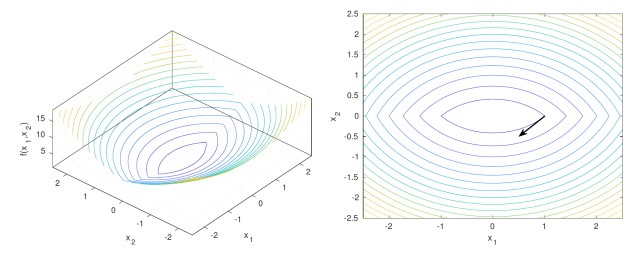
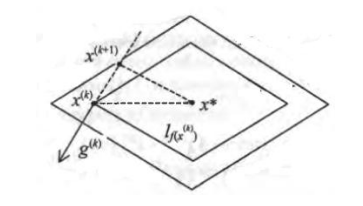
This differs from classical gradient descent, where the negative gradient always points towards decreasing function values.
Example of Subgradient Descent
Consider the function:
with a subgradient at
Since
An important property:
shows that subgradient descent does not necessarily decrease function values at each step.
Additionally:
suggests that the iterates remain bounded, even if the function value does not strictly decrease.
How to Choose a Step Size?
In subgradient descent, the step size
1. Diminishing Step Size:
A common approach is to use a sequence
The plus sign (
-
Selecting the steepest subgradient
- If multiple subgradients exist (e.g., at a nondifferentiable point), we might choose the one with the largest norm or the steepest > descent direction.
- This is useful in algorithms like normalized subgradient descent to ensure consistent step sizes.
-
Selecting a specific element in a structured way
- Some optimization methods require a deterministic or structured choice of subgradient.
- The plus sign may indicate a particular rule for selecting a subgradient, e.g., the right-hand derivative in one-dimensional cases.
-
Right subgradient in nonsmooth analysis
- In some contexts (like directional derivatives),
may refer to the right subdifferential, meaning we consider > subgradients corresponding to increasing values of .
- In some contexts (like directional derivatives),
where
Three typical choices:
, where is a constant. . .
2. If the optimal function value
The update rule can be modified as:
3. Using the best observed function value:
Define:
and use:
This ensures convergence by tracking the best function value observed so far.
Convergence of Subgradient Descent
Lipschitz Convex Functions
If
then choosing the constant step size:
yields:
Strongly Convex Functions
If
yields:
where:
This shows that subgradient descent converges slower than standard gradient descent, but still guarantees progress over time.
Subgradient Descent for Constrained Optimization
The projected subgradient method is used for constrained optimization, where
The update step includes a projection onto the feasible set:
-
Compute:
-
Project onto
:
This ensures that all iterates remain feasible.
A key inequality that governs convergence:
This highlights the trade-off between step size, function values, and convergence.
Summary
- Subgradient descent is an extension of gradient descent for non-smooth convex functions.
- The step size must be carefully chosen to ensure convergence.
- Convergence is slower compared to gradient descent but still guaranteed.
- Projected subgradient methods allow constrained optimization by keeping iterates within a feasible set.
This method is widely used in non-smooth optimization problems, such as L1-regularized learning (Lasso) and robust optimization.