PROJECTED GRADIENT DESCENT
- Gradient-based optimization is widely used in various fields.
- Many problems include constraints that must be satisfied.
- Projected Gradient Descent (PGD) extends standard gradient descent by ensuring iterates remain feasible within a given constraint set.
Constrained Minimization
Let
Lemma 1
If
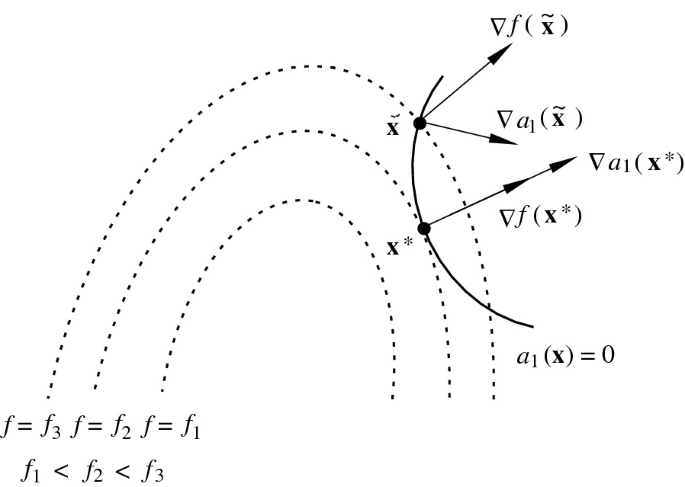
Existence of a Minimum for constrained optimization.
Definition of Projected Gradient Descent
Consider the constrained optimization problem:
where
where
Projected Gradient Descent Algorithm
Initialization
Choose an initial point
Iterative Steps
For
- Compute the gradient:
- Take a gradient step:
- Project onto the feasible set
:
Repeat until convergence.
Theorem 1: Step Size Selection
If
then the Projected Gradient Method converges for step sizes satisfying:
A common choice is:
Theorem 2: Convergence Rate
Let
with . for all .
Where
Choosing the constant step size:
Projected Gradient Descent yields:
Looks the same as the Gradient Descent convergence rate!
Theorem 3: Convergence Rate (Smooth Case)
Let
Projected Gradient Descent yields:
Looks similar to the Gradient Descent smooth case!
Theorem 4: Error Bound
If
Projected Gradient Descent satisfies:
-
Geometric Decrease in Distance to
: -
Exponential Decrease in Function Value:
Thus, error decreases exponentially as iterations proceed.
Summary:
- Projected Gradient Descent (PGD) is an extension of gradient descent for constrained problems.
- It ensures that iterates remain feasible within the constraint set
. - The projection step ensures valid updates.
- Step sizes are chosen to ensure convergence based on properties of the function (e.g., smoothness).
- Convergence rate depends on problem smoothness and strong convexity.
PGD is widely used in optimization, machine learning, and constrained convex problems. 🚀