GRADIENT DESCENT
Gradient descent is an iterative optimization algorithm used to find the minimum of a differentiable function. Given a function
We need to find such a point
So, the goal is to find the point
The key idea is to start from an initial point
Iterative Algorithm
-
Choose an initial point
. -
Update rule: The next point is computed using the gradient:
Here,
is the step size (learning rate). -
Repeat this process until a stopping criterion is satisfied.
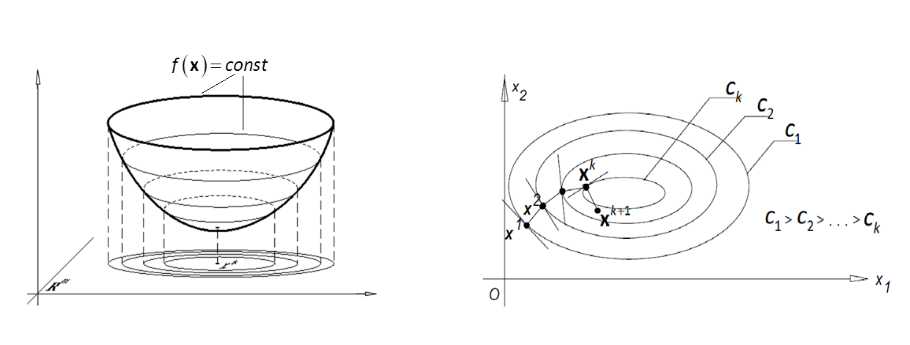
Geometric Interpretation
- Gradient descent follows the steepest descent direction to minimize the function.
- In a 3D bowl-like function, each iteration moves the point downhill until reaching the minimum.
- The algorithm follows contour lines in 2D, converging towards the optimal point.
Average Error in Gradient Descent
Over the first
Step Size Problems
- If
is too small, the algorithm converges slowly. - If
is too large, the algorithm may overshoot and fail to converge.
Choosing the Step Size
Theorem 1: Bounded Gradient
For a convex and differentiable function
Where
Choosing the step size:
yields:
Thus, the average error decreases as
Theorem 2: Smooth Functions
If
gradient descent satisfies:
So, the function value decreases at each iteration.
Theorem 3: Smooth and Convex Functions
For a convex and differentiable function with smoothness parameter
ensures:
This means the function value converges to the minimum at a rate of
Stopping Criteria
To stop the iteration process, we use one of the following conditions:
-
Gradient norm is small:
-
Sum of gradient components is small:
-
Function values stop decreasing:
These conditions ensure that the algorithm stops when the function is close to the minimum.
Summary
- Gradient descent iteratively moves in the direction of steepest descent.
- Step size
determines the trade-off between speed and stability. - Theoretical results guarantee convergence under appropriate conditions.
- Stopping criteria ensure we do not perform unnecessary iterations.
Gradient descent is widely used in machine learning, optimization, and deep learning due to its simplicity and efficiency! 🚀